|
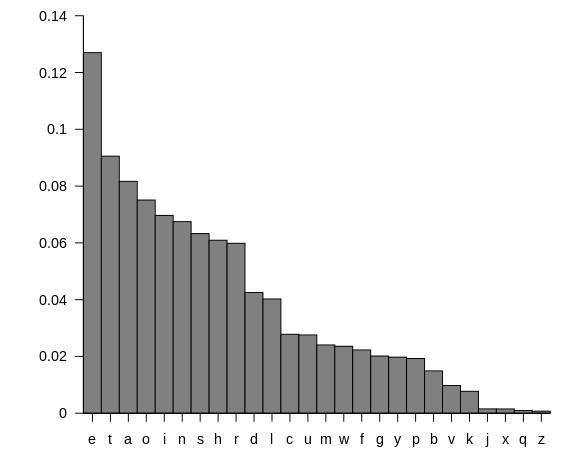
三、实验数据选择及分析 3.1 错误容忍度与文本长度对破解精度的影响 本节同时分析错误容忍度与文本长度对破解精度的影响。 同时分析这两个因素的动机在于其补偿关系,即较长的文本可以在更低的容忍度下达到相同的破解精度,而较短的文本则需要更高的容忍度来补偿统计数据的不足。进行单因子变化分析无法捕捉到这一关系。同时分析这两个维度亦有助于理解下文提出权方正确率的动机。 本节笔者截取了A Strong Appeal.doc第一章正文中的前250、500、1000、2000、4000与8000有效英语字母作为实验数据。加密后使用代码分析六段文本在容忍度为1~8的情况下的解密正确率。数据见下表,可视化见图1。 表1. 解密正确率—字母数/容忍度表 图1. 解密正确率—字母数/容忍度三维柱状图 表1与图1的数据显示,文本长度相同的前提下,错误容忍度越大,解密准确率越高。随着文本长度的增加,达到相同准确率所需的容忍度逐渐降低。例如,250字母文本需要容忍度7才能达到100%准确率,而8000字母文本仅需容忍度3即可实现完全破解。这一现象印证了两个因素的补偿关系,即较长的文本可以在更低的容忍度下达到相同的破解精度,而较短的文本则需要更高的容忍度来补偿统计数据的不足。 值得注意的是,字母数为1000的文本相比字母数为250的文本,T1低了11%以上。为了分析这一现象,下表列出了字母数为250-1000-4000的不同加密文本切片中的字母频率。频率与标准字母频率相同的标为绿色,偏差为1的标为黄色,偏差为2及以上的标为红色。可以看到,字母数为1000的文本中红色较多,但最高频字母h(对应明文e)符合标准频率分布,而字母数为250的文本中红色较少,但h与标准频率有1位偏差。这在一定程度上体现了容忍度算法的局限性,因为1000字母数的文本相比250字母数的文本提供了更多信息,而这种信息的冗余并不会导致破译变难。 表2. 字母数为250、1000与4000的文本字母频率偏差表 笔者因此提出计算权方正确率: 该算法中,25是26个字母的最大可能排名差(从第0位到第25位),作为归一化分母;取平方可对排名偏差进行非线性惩罚,对0-1的位次偏差给予的惩罚大于24-25的位次偏差给予的惩罚;最终将结果归一化到[0,1]区间,便于比较。 权方正确率可对字母数为1000的文本正确对e进行排名给予积极反应。事实上,字母数为250、1000和4000的文本,其权方正确率分别为0.447、0.447与0.434,这相比其在Tolerance1下的正确率,0.558、0.442和0.876更能代表文本的自身频率分布与标准分布的固有匹配程度。 此外,经笔者验证,权方正确率较高的文本,在文本长度相同的情况下,其达到100%准确率所需的容忍度较低,但反之不适用。 综上,错误容忍度与文本长度仅能体现不同的错误容忍度达到100%准确率与文本长度的补偿关系,而无法客观代表文本的自身频率分布与标准分布的固有匹配程度。这一局限性源于该算法对所有在容忍度外的字母的赋予权重0,而对于容忍度内的字母赋予权重1,是一种离散而二分的评估方式。而笔者提出的权方正确率赋予所有字母非线性惩罚,代表文本内部的一种固有属性,与文本长度相关性低,是一种连续且加权的评估方式,可用于后续小节的进一步分析。 3.2 文本类型与主题对破解精度的影响 本节基于前文提出的权方正确率、容忍度1和容忍度2三个指标,分析文本类型与主题对破解精度的影响。 实验数据包括文学作品、时事新闻与学术论文三种类型。文学作品主题包括小说、自传与政治经济评论各一;新闻主题包括UN可持续发展城市、CNN文学影视与CNN动物保护各一;学术论文主题包括法律伦理、游戏媒介理论与网络安全各一。每段文本截取前3000字母,从而排除文本长度对容忍度的影响。 表3. 不同文本类型与主题的权方正确率与容忍度表 观察数据显示,联合国可持续发展城市新闻与三篇论文正确率最高,因为此类学术与官方文献通常采用规范严谨的书面语,用词准确且符合标准英语的统计特征。相比之下,CNN新闻报道中包含较多口语化表达与访谈内容,语言风格相对灵活,致使其权方正确率相较UN的新闻略有降低。而自传文本作者为伍迪·艾伦,其语言风格极具个人特色,用词多元且常出现生僻词汇,因而权方正确率为所选文本中最低。 总体而言,不同文本的权方正确率呈现出一定规律:官方文献高于个人访谈,学术性内容高于个性化书写。这一分布趋势与选取文本时的预期基本一致,反映出文本类型与语言规范性对字母频率分布的影响。 容忍度为1的情况下要求字母的实测频率排名与标准排名差不超过1,该标准过于严格,导致其评估结果易受文本特异性内容的干扰,代表性有限。可以看到,CNN的文学影视新闻的T1值高达0.951,而网络安全论文的T1值仅为0.470,其余均落在0.787±0.019的区间内。前二者巨大差异不符合文本选择的预期,且其余值没有区分度。采用该指标无法进行有效区分。 容忍度为2的情况允许字母排名在标准排名的前后共5个位置内浮动,此宽松条件导致该指标在多数文本在字母数达到3000时即可迅速达到极高的准确率,从而丧失了有效的区分能力。在九类不同文本中,有六类文本的T2值均超过0.95。这表明T2指标对于中等长度的大多数文本类型而言,其评估已趋于饱和,无法进一步揭示不同文本在频率分布上存在的细小差异。 综上,通过对三类评估指标的对比分析可见:权方正确率能够稳定反映不同文本类型与主题在字母频率分布上的内在差异,其评估结果与文本的语言规范性程度高度吻合,呈现官方文献高于个人访谈,学术性内容高于个性化书写的特征,证明了该指标在衡量文本固有统计特性方面的有效性与区分度。 相比之下,容忍度指标在评估中则显现出明显局限:T1因标准过于严苛,区分度与稳定性均有限;T2则因标准过于宽松,在中等长度文本上即出现评估饱和,丧失了区分不同文本类型的能力。 因此,在分析文本类型与主题对频率分析法破解精度的影响时,权方正确率相比传统容忍度指标更具参考价值。
| 

 发表于 3-16-2026 19:21:56
发表于 3-16-2026 19:21:56